
What is all this Reliability Stuff anyhow?
First up – keep away from Wikipedia, the maths, and all the complicated stuff. Reliability is a large engineering discipline in its own right but for our purposes we can simplify a lot.
We need to define a few things, because this helps with clarity.
Failure: This means a measurable or discoverable condition of equipment which is not as intended. For us, in electronics, a simple example is “oops the magic smoke came out and it does not work any more”. The failure is not the smoke (that’s a symptom) – the failure is that the thing does not work any more.
(Pedants corner: Failure includes intermittent operation, broken solder joints where no magic smoke comes out, and all manner of other cases of operation that is not intended.)
Fault: The fault is the underlying thing that has gone wrong, which led to the failure.
Faults are important for designers: from the failure, if you can work out the underlying fault, then something can be done to try and prevent this happening again – perhaps a design change.
Failures are what we see or can measure. Fault is what caused the failure.
MTBF: This is an acronym: Mean Time Between Failures. That is – if you have a large enough sample of equipment that has failed (so you can calculate an average), then this is the mean time (ie, the average time) between failures for a given product. The MTBF is normally expressed in HOURS.
Failure Rate: This is just 1/MTBF. Oops sorry… the maths is starting.
Example:
- An MTBF of 1000 hours means that, on average, a large number of samples of the item will see a failure happen every 1000 hours. Some will last longer, some not so long, but on average, it would be 1000 hours.
- The same item would have a failure rate of 1/1000 = 0.001 failures per hour.
(In general, MTBF is easier to understand compared to small numbers).
FIT: Another acronym, meaning: Failures In Time. This is the failure rate per billion hours. Take that failure rate, multiply by 1 billion.
Example:
- Using our above example, with a failure rate 0.001, the FIT would be 1 billion * 0.001 = 1 million failures in time (failures per billion hours or operation).
Most of the time, there’s little need to worry about failure rates and FIT. The MTBF tends to have the focus. The reason for including the description of failure rate and FIT is that these are needed for some kinds of reliability analysis.
The Bathtub Curve: So called due to the characteristic shape:
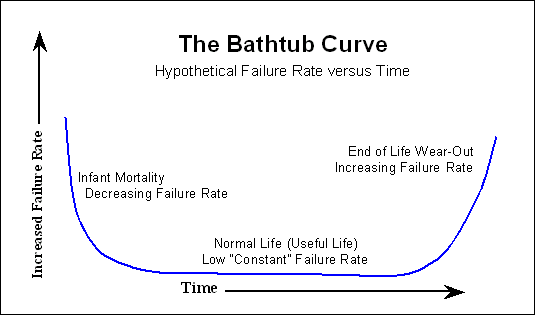
The simple explanation of the bathtub curve:
- Product may have early life failures, perhaps due to manufacturing defects;
- Then there is a long period of normal operation, with a constant and low failure rate caused by normal wear and tear and the random things that happen during the product life; and
- At the end of the product life, the failure rates increase due to wear-out.
Manufacturer warranties are aimed to deal with the early life failures. Typically, early life failures show up in the first few hundred hours of operation for almost all electronic products.